
How do search engines work?
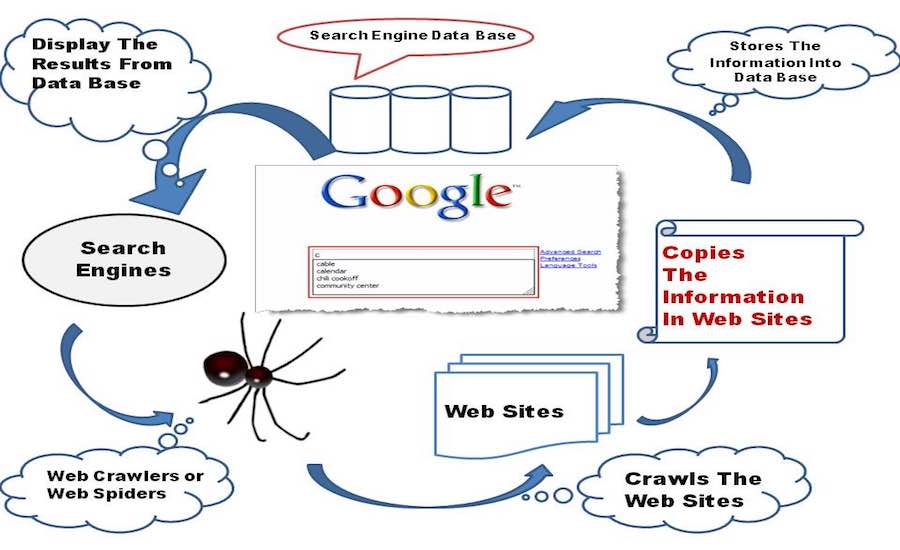
The work of the search engine is divided into three stages, i.e., crawling, indexing, and retrieval.
Crawling
This is the first step in which a search engine uses web crawlers to find out the webpages on the World Wide Web. A web crawler is a program used by Google to make an index. It is designed for crawling, which is a process in which the crawler browses the web and stores the information about the webpages visited by it in the form of an index.
So, the search engines have the web crawlers or spiders to perform crawling, and the task of crawler is to visit a web page, read it, and follow the links to other web pages of the site. Each time the crawler visits a webpage, it makes a copy of the page and adds its URL to the index. After adding the URL, it regularly visits the sites like every month or two to look for updates or changes.
Indexing
After a page is discovered, Google tries to understand what the page is about. This process is called indexing. Google analyzes the content of the page, catalogs images and video files embedded on the page, and otherwise tries to understand the page. This information is stored in the Google index, a huge database stored in many, many (many!) computers.
To improve your page indexing:
-
Create short, meaningful page titles.
-
Use page headings that convey the subject of the page.
-
Use text rather than images to convey content. (Google can understand some image and video, but not as well as it can understand text.
Retrieval
When a user types a query, Google tries to find the most relevant answer from its index based on many factors. Google tries to determine the highest quality answers, and factor in other considerations that will provide the best user experience and most appropriate answer, by considering things such as the user's location, language, and device (desktop or phone). For example, searching for "bicycle repair shops" would show different answers to a user in Paris than it would to a user in Hong Kong. Google doesn't accept payment to rank pages higher, and ranking is done programmatically.
#SEOCOMPANYINJAIPUR #SEOCOMPANYINDELHI #SEOCOMPANYINGURGAON #SEOCOMPANYININDIA #SEOCOMPANY #SEOTRAINING
You can share this story by using your social accounts: